

一、概念及详解
在各种体系的计算机中通常采用的字节存储机制主要有两种: Big-Endian和Little-Endian,即大端模式和小端模式。
Big-Endian和Little-Endian的定义如下:
1) Little-Endian:就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
2) Big-Endian:就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。

举一个例子,比如16进制数字0x12345678在内存中的表示形式为:
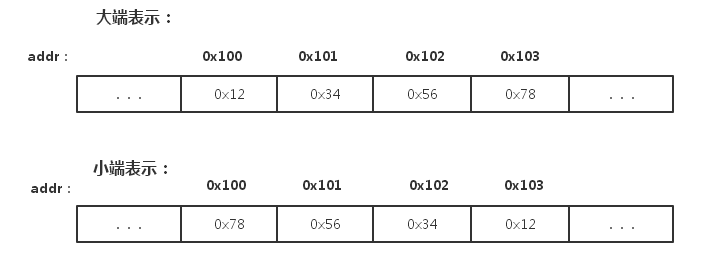
大端小端没有谁优谁劣,各自优势便是对方劣势:
小端模式 :强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
大端模式 :符号位的判定固定为第一个字节,容易判断正负。
为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的x86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
如何判断机器的字节序
1 | int i=1; |
或者使用联合体union:
1 | //return 1 : little-endian |
因为联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性就可以轻松地获得了CPU对内存采用Little-endian还是Big-endian模式读写。
顺便可以看下Java中如何判断字节序。Java NIO中的ByteBuffer类使用了Bits.byteOrder()来判断字节序,源代码如下:
1 | class Bits { |
常见的字节序
一般操作系统都是小端,而通讯协议是大端的。
常见CPU的字节序
| 大小端 | CPU |
|---|---|
| Big Endian | PowerPC、IBM、Sun |
| Little Endian | x86、DEC |
ARM既可以工作在大端模式,也可以工作在小端模式。
常见文件的字节序
| 文件格式 | 大小端 |
|---|---|
| Adobe PS | Big Endian |
| BMP | Little Endian |
| DXF(AutoCAD) | Variable |
| GIF | Little Endian |
| JPEG | Big Endian |
| MacPaint | Big Endian |
| RTF | Little Endian |
另外,Java和所有的网络通讯协议都是使用Big-Endian的编码。
大端小端的转换方法

1 | #define BigtoLittle16(A) ((((uint16)(A) & 0xff00) >> 8) | \ |