

概述
因为健忘,加上对各种排序算法理解不深刻,过段时间面对排序就蒙了。所以决定对我们常见的这几种排序算法进行统一总结,强行学习。首先罗列一下常见的十大排序算法:
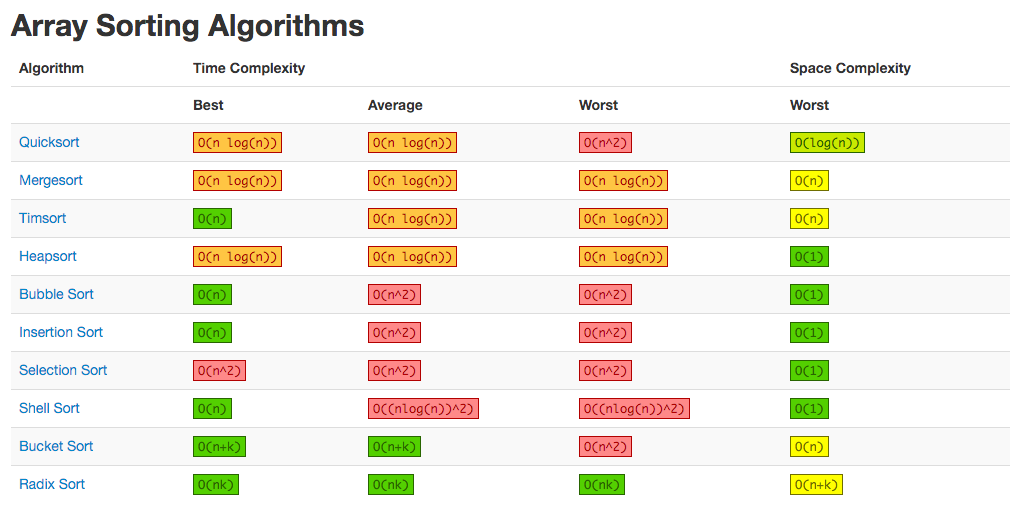
- 直接插入排序
- 希尔排序
- 简单选择排序
- 堆排序
- 冒泡排序
- 快速排序
- 归并排序
- 基数排序
我们讨论的这八大排序算法的实现可以参考我的Github:SortAlgorithms,其中也包括了排序测试模块[Test.java]和排序算法对比模块[Bench.java],大家可以试运行。
它们都属于内部排序,也就是只考虑数据量较小仅需要使用内存的排序算法,他们之间关系如下:
$$ \begin{cases} 内部排序 \begin{cases} 插入排序 \begin{cases} 直接插入排序\\ 希尔排序 \end{cases} \\ 选择排序 \begin{cases} 简单选择排序\\ 堆排序 \end{cases} \\ 交换排序 \begin{cases} 冒泡排序\\ 快速排序 \end{cases} \\ 归并排序\\ 基数排序 \end{cases} \\ 外部排序 \end{cases} $$一、直接插入排序(Insertion Sort)
插入排序的设计初衷是往有序的数组中快速插入一个新的元素。它的算法思想是:把要排序的数组分为了两个部分, 一部分是数组的全部元素(除去待插入的元素), 另一部分是待插入的元素; 先将第一部分排序完成, 然后再插入这个元素. 其中第一部分的排序也是通过再次拆分为两部分来进行的.
插入排序由于操作不尽相同, 可分为 直接插入排序 , 折半插入排序(又称二分插入排序), 链表插入排序 , 希尔排序 。我们先来看下直接插入排序。
1、基本思想
直接插入排序的基本思想是:将数组中的所有元素依次跟前面已经排好的元素相比较,如果选择的元素比已排序的元素小,则交换,直到全部元素都比较过为止。
2、算法描述
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
①. 从第一个元素开始,该元素可以认为已经被排序
②. 取出下一个元素,在已经排序的元素序列中从后向前扫描
③. 如果该元素(已排序)大于新元素,将该元素移到下一位置
④. 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
⑤. 将新元素插入到该位置后
⑥. 重复步骤②~⑤
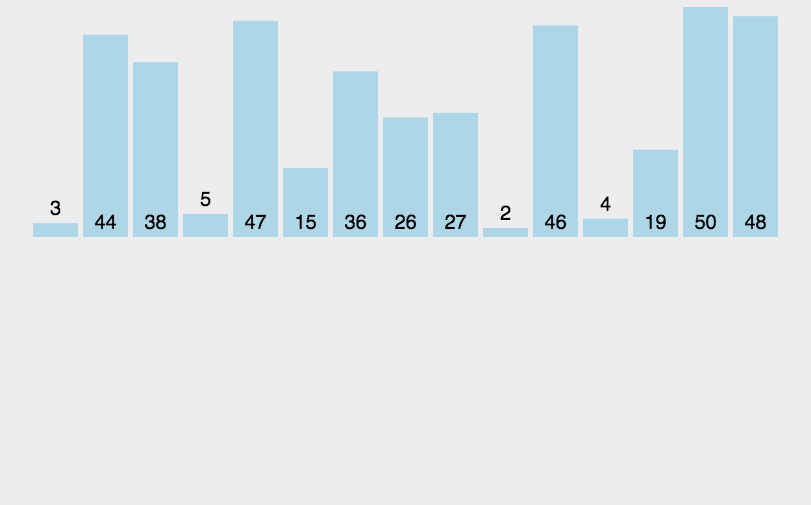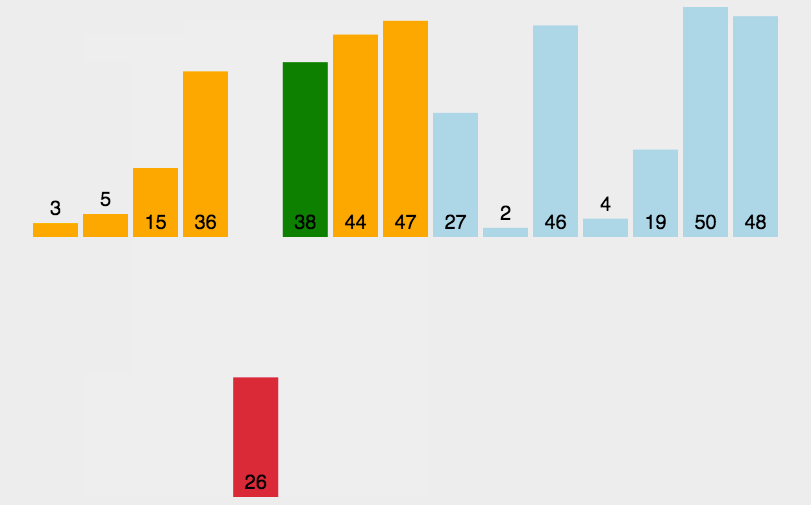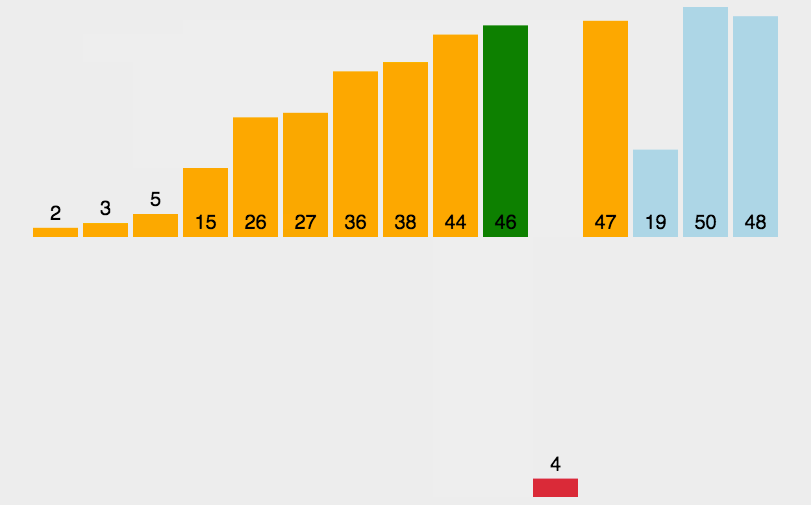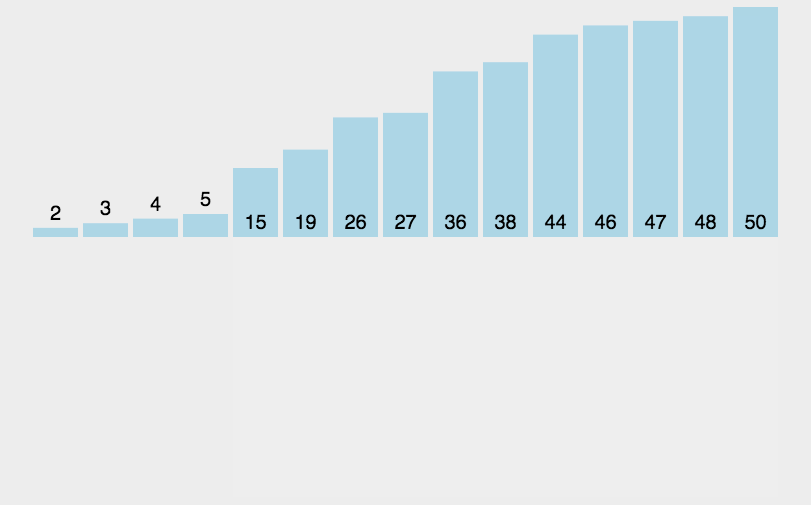
算法实现中比较有意思的一点是,在每次比较操作发现取出来的新元素小于等于已排序的元素时,可以将已排序的元素移到下一位置,然后将取出来的新元素插入该位置(即相邻位置对调),接着再与前面的已排序的元素进行比较,如上图所示,这样做缺点是交换操作代价比较大。另一种做法是:将新元素取出(挖坑),从左到右依次与已排序的元素比较,如果已排序的元素大于取出的新元素,那么将该元素移动到下一个位置(填坑),接着再与前面的已排序的元素比较,直到找到已排序的元素小于等于新元素的位置,这时再将新元素插入进去。就像基本思想中的动图演示的那样。
如果比较操作的代价比交换操作大的话,可以采用二分查找法来减少比较操作的数目。可以认为是插入排序的一个变种,称为二分查找插入排序。
3、代码实现
1 | /** |
直接插入排序复杂度如下:
- 最好情况下,排序前对象已经按照要求的有序。比较次数(KCN):$n−1$;移动次数(RMN)为$0$。则对应的时间复杂度为$O(n)$。
- 最坏情况下,排序前对象为要求的顺序的反序。第i趟时第i个对象必须与前面i个对象都做排序码比较,并且每做1次比较就要做1次数据移动(从上面给出的代码中看出)。比较次数(KCN):$\sum_{i=1}^{n-1}i=\frac{n(n-1)}{2}\approx \frac{n^{2}}{2}$ ; 移动次数(RMN)为:$\sum_{i=1}^{n-1}i=\frac{n(n-1)}{2}\approx \frac{n^{2}}{2}$。则对应的时间复杂度为$O(n^{2})$。
- 如果排序记录是随机的,那么根据概率相同的原则,在平均情况下的排序码比较次数和对象移动次数约为$\frac{n^{2}}{2}$,因此,直接插入排序的平均时间复杂度为$O(n^{2})$。
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(n²) | O(n) | O(n²) | O(1) |
Tips: 由于直接插入排序每次只移动一个元素的位, 并不会改变值相同的元素之间的排序, 因此它是一种稳定排序。
二、希尔排序(Shell Sort)
第一个突破O(n^2)的排序算法;是简单插入排序的改进版;它与插入排序的不同之处在于,它会优先比较距离较远的元素。
希尔排序,也称递减增量排序算法,1959年Shell发明。是插入排序的一种高速而稳定的改进版本。
希尔排序是先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
1、基本思想
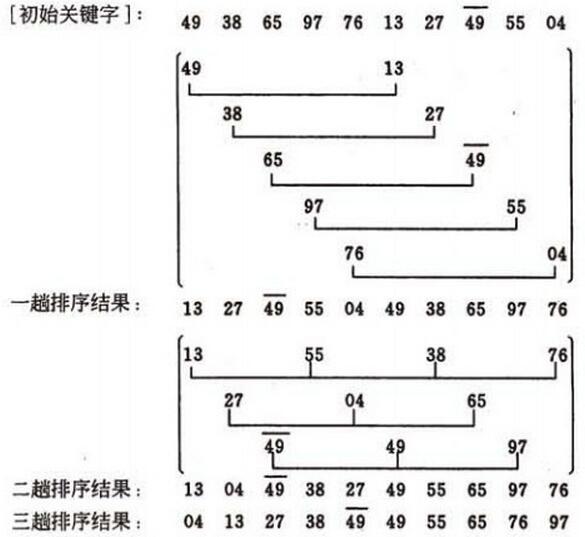
将待排序数组按照步长gap进行分组,然后将每组的元素利用直接插入排序的方法进行排序;每次再将gap折半减小,循环上述操作;当gap=1时,利用直接插入,完成排序。
可以看到步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作。一般来说最简单的步长取值是初次取数组长度的一半为增量,之后每次再减半,直到增量为1。更好的步长序列取值可以参考维基百科。
2、算法描述
①. 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;(一般初次取数组半长,之后每次再减半,直到增量为1)
②. 按增量序列个数k,对序列进行k 趟排序;
③. 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
3、代码实现
以下是我自己的实现,可以看到实现很幼稚,但是好处是理解起来很简单。因为没有经过任何的优化,所以不建议大家直接使用。建议对比下方的维基百科官方实现代码,特别是步长取值策略部分。
1 | /** |
注意:
①. 第一层for循环表示一共有多少个增量。增量的序列的个数,就是希尔排序的趟数。上面的增量序列为: arr.length/2, arr.length/2/2, arr.length/2/2/2, .... 2, 1
②. 里层的两个for循环,实际上就是以一个gap拆分为一组的组内插入排序。
下面是维基百科官方实现,大家注意gap步长取值部分:
1 | /** |
以下是希尔排序复杂度:
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(nlog2 n) | O(nlog2 n) | O(nlog2 n) | O(1) |
三、选择排序(Selection Sort)
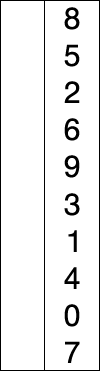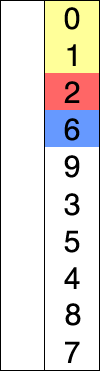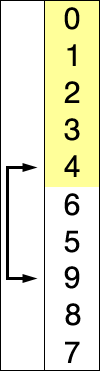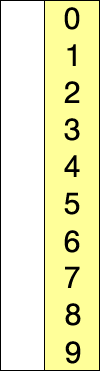
从算法逻辑上看,选择排序是一种简单直观的排序算法,在简单选择排序过程中,所需移动记录的次数比较少。
1、基本思想
选择排序的基本思想:比较 + 交换。
在未排序序列中找到最小(大)元素,存放到未排序序列的起始位置。在所有的完全依靠交换去移动元素的排序方法中,选择排序属于非常好的一种。
2、算法描述
①. 从待排序序列中,找到关键字最小的元素;
②. 如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;
③. 从余下的 N - 1 个元素中,找出关键字最小的元素,重复①、②步,直到排序结束。
3、代码实现
选择排序比较简单,以下是我自己的实现,跟官方版差不多,所以完全可以参考。
1 | /** |
以下是选择排序复杂度:
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(n²) | O(n²) | O(n²) | O(1) |
选择排序的简单和直观名副其实,这也造就了它”出了名的慢性子”,无论是哪种情况,哪怕原数组已排序完成,它也将花费将近n²/2次遍历来确认一遍。即便是这样,它的排序结果也还是不稳定的。 唯一值得高兴的是,它并不耗费额外的内存空间。
四、堆排序(Heap Sort)
1991年的计算机先驱奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德(Robert W.Floyd) 和威廉姆斯(J.Williams) 在1964年共同发明了著名的堆排序算法(Heap Sort).
堆的定义如下:$n$个元素的序列 $\left\{{k_1,k_2,···,k_n}\right\}$ 当且仅当满足下关系时,称之为堆。
$$ \left\{ \begin{aligned} k_i & \leqslant k_{2i} \\ k_i & \leqslant k_{2i+1} \end{aligned} \right. \quad 或 \quad \left\{ \begin{aligned} k_i & \geqslant k_{2i} \\ k_i & \geqslant k_{2i+1} \end{aligned} \right. \quad (i = 1,2,···, \left \lfloor { \frac{n}{2} } \right \rfloor ) $$把此序列对应的二维数组看成一个完全二叉树。那么堆的含义就是:完全二叉树中任何一个非叶子节点的值均不大于(或不小于)其左,右孩子节点的值。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。因此我们可使用大顶堆进行升序排序, 使用小顶堆进行降序排序。
1、基本思想
此处以大顶堆为例,堆排序的过程就是将待排序的序列构造成一个堆,选出堆中最大的移走,再把剩余的元素调整成堆,找出最大的再移走,重复直至有序。
2、算法描述
①. 先将初始序列$K[1..n]$建成一个大顶堆, 那么此时第一个元素$K_1$最大, 此堆为初始的无序区.
②. 再将关键字最大的记录$K_1$ (即堆顶, 第一个元素)和无序区的最后一个记录 $K_n$ 交换, 由此得到新的无序区$K[1..n-1]$和有序区$K[n]$, 且满足$K[1..n-1].keys \leqslant K[n].key$
③. 交换$K_1$ 和 $K_n$ 后, 堆顶可能违反堆性质, 因此需将$K[1..n-1]$调整为堆. 然后重复步骤②, 直到无序区只有一个元素时停止.
动图效果如下所示:

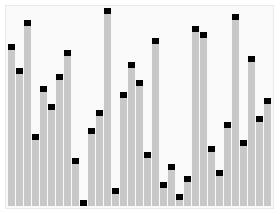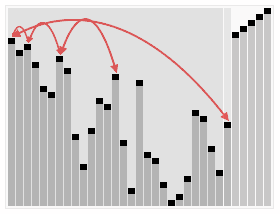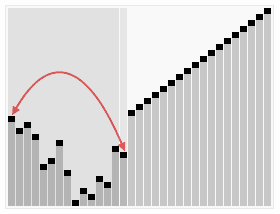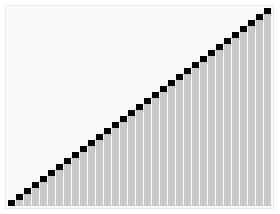
3、代码实现
从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆函数,二是反复调用建堆函数以选择出剩余未排元素中最大的数来实现排序的函数。
总结起来就是定义了以下几种操作:
- 最大堆调整(Max_Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
- 创建最大堆(Build_Max_Heap):将堆所有数据重新排序
- 堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算
对于堆节点的访问:
- 父节点i的左子节点在位置:
(2*i+1); - 父节点i的右子节点在位置:
(2*i+2); - 子节点i的父节点在位置:
floor((i-1)/2);
1 | /** |
注: x>>1 是位运算中的右移运算, 表示右移一位, 等同于x除以2再取整, 即 x>>1 == Math.floor(x/2) .
以上,
①. 建立堆的过程, 从length/2 一直处理到0, 时间复杂度为O(n);
②. 调整堆的过程是沿着堆的父子节点进行调整, 执行次数为堆的深度, 时间复杂度为O(lgn);
③. 堆排序的过程由n次第②步完成, 时间复杂度为O(nlgn).
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| $O(n \log_{2}n)$ | $O(n \log_{2}n)$ | $O(n \log_{2}n)$ | O(1) |
Tips: 由于堆排序中初始化堆的过程比较次数较多, 因此它不太适用于小序列. 同时由于多次任意下标相互交换位置, 相同元素之间原本相对的顺序被破坏了, 因此, 它是不稳定的排序.
五、冒泡排序(Bubble Sort)

我想对于它每个学过C语言的都会了解,这可能是很多人接触的第一个排序算法。
1、基本思想
冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
2、算法描述
冒泡排序算法的运作如下:
①. 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
②. 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
③. 针对所有的元素重复以上的步骤,除了最后一个。
④. 持续每次对越来越少的元素重复上面的步骤①~③,直到没有任何一对数字需要比较。
3、代码实现
冒泡排序需要两个嵌套的循环. 其中, 外层循环移动游标; 内层循环遍历游标及之后(或之前)的元素, 通过两两交换的方式, 每次只确保该内循环结束位置排序正确, 然后内层循环周期结束, 交由外层循环往后(或前)移动游标, 随即开始下一轮内层循环, 以此类推, 直至循环结束.
1 | /** |
以下是冒泡排序算法复杂度:
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(n²) | O(n) | O(n²) | O(1) |
冒泡排序是最容易实现的排序, 最坏的情况是每次都需要交换, 共需遍历并交换将近n²/2次, 时间复杂度为O(n²). 最佳的情况是内循环遍历一次后发现排序是对的, 因此退出循环, 时间复杂度为O(n). 平均来讲, 时间复杂度为O(n²). 由于冒泡排序中只有缓存的temp变量需要内存空间, 因此空间复杂度为常量O(1).
Tips: 由于冒泡排序只在相邻元素大小不符合要求时才调换他们的位置, 它并不改变相同元素之间的相对顺序, 因此它是稳定的排序算法.
六、快速排序(Quick Sort)
快速排序(Quicksort)是对冒泡排序的一种改进,借用了分治的思想,由C. A. R. Hoare在1962年提出。
1、基本思想
快速排序的基本思想:挖坑填数+分治法。
首先选一个轴值(pivot,也有叫基准的),通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
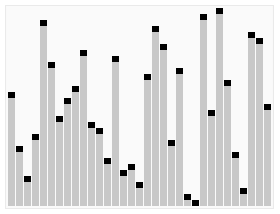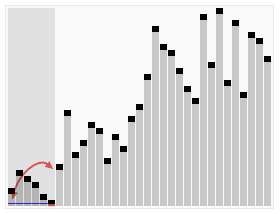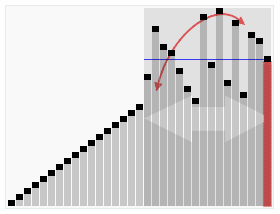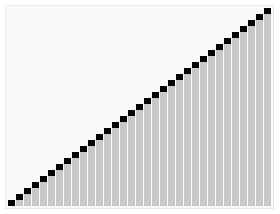
2、算法描述
快速排序使用分治策略来把一个序列(list)分为两个子序列(sub-lists)。步骤为:
①. 从数列中挑出一个元素,称为”基准”(pivot)。
②. 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
③. 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归到最底部时,数列的大小是零或一,也就是已经排序好了。这个算法一定会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
3、代码实现
用伪代码描述如下:
①. i = L; j = R; 将基准数挖出形成第一个坑a[i]。
②.j--,由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
③.i++,由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
④.再重复执行②,③二步,直到i==j,将基准数填入a[i]中
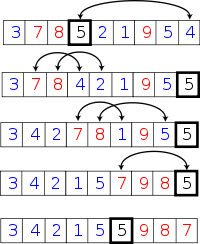
1 | /** |
上面是递归版的快速排序:通过把基准temp插入到合适的位置来实现分治,并递归地对分治后的两个划分继续快排。那么非递归版的快排如何实现呢?
因为递归的本质是栈,所以我们非递归实现的过程中,可以借助栈来保存中间变量就可以实现非递归了。在这里中间变量也就是通过Pritation函数划分区间之后分成左右两部分的首尾指针,只需要保存这两部分的首尾指针即可。
1 | /** |
快速排序是通常被认为在同数量级(O(nlog2n))的排序方法中平均性能最好的。但若初始序列按关键码有序或基本有序时,快排序反而蜕化为冒泡排序。为改进之,通常以“三者取中法”来选取基准记录,即将排序区间的两个端点与中点三个记录关键码居中的调整为支点记录。快速排序是一个不稳定的排序方法。
以下是快速排序算法复杂度:
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(nlog₂n) | O(nlog₂n) | O(n²) | O(1)(原地分区递归版) |
快速排序排序效率非常高。 虽然它运行最糟糕时将达到O(n²)的时间复杂度, 但通常平均来看, 它的时间复杂为O(nlogn), 比同样为O(nlogn)时间复杂度的归并排序还要快. 快速排序似乎更偏爱乱序的数列, 越是乱序的数列, 它相比其他排序而言, 相对效率更高.
Tips: 同选择排序相似, 快速排序每次交换的元素都有可能不是相邻的, 因此它有可能打破原来值为相同的元素之间的顺序. 因此, 快速排序并不稳定.
七、归并排序(Merging Sort)
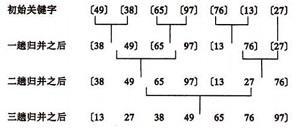
归并排序是建立在归并操作上的一种有效的排序算法,1945年由约翰·冯·诺伊曼首次提出。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用,且各层分治递归可以同时进行。
1、基本思想
归并排序算法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
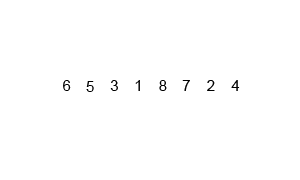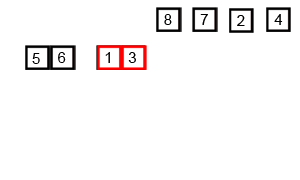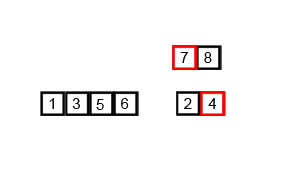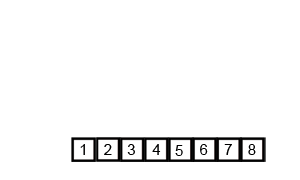
2、算法描述
归并排序可通过两种方式实现:
- 自上而下的递归
- 自下而上的迭代
一、递归法(假设序列共有n个元素):
①. 将序列每相邻两个数字进行归并操作,形成 floor(n/2)个序列,排序后每个序列包含两个元素;
②. 将上述序列再次归并,形成 floor(n/4)个序列,每个序列包含四个元素;
③. 重复步骤②,直到所有元素排序完毕。
二、迭代法
①. 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
②. 设定两个指针,最初位置分别为两个已经排序序列的起始位置
③. 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
④. 重复步骤③直到某一指针到达序列尾
⑤. 将另一序列剩下的所有元素直接复制到合并序列尾
3、代码实现
归并排序其实要做两件事:
- 分解:将序列每次折半拆分
- 合并:将划分后的序列段两两排序合并
因此,归并排序实际上就是两个操作,拆分+合并
如何合并?
L[first…mid]为第一段,L[mid+1…last]为第二段,并且两端已经有序,现在我们要将两端合成达到L[first…last]并且也有序。
首先依次从第一段与第二段中取出元素比较,将较小的元素赋值给temp[]
重复执行上一步,当某一段赋值结束,则将另一段剩下的元素赋值给temp[]
此时将temp[]中的元素复制给L[],则得到的L[first…last]有序
如何分解?
在这里,我们采用递归的方法,首先将待排序列分成A,B两组;然后重复对A、B序列
分组;直到分组后组内只有一个元素,此时我们认为组内所有元素有序,则分组结束。
这里我写了递归算法如下:
1 | /** |
由上, 长度为n的数组, 最终会调用mergeSort函数2n-1次。通过自上而下的递归实现的归并排序, 将存在堆栈溢出的风险。
以下是归并排序算法复杂度:
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(nlog₂n) | O(nlog₂n) | O(nlog₂n) | O(n) |
从效率上看,归并排序可算是排序算法中的”佼佼者”. 假设数组长度为n,那么拆分数组共需logn,, 又每步都是一个普通的合并子数组的过程, 时间复杂度为O(n), 故其综合时间复杂度为O(nlogn)。另一方面, 归并排序多次递归过程中拆分的子数组需要保存在内存空间, 其空间复杂度为O(n)。
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是
O(n log n)的时间复杂度。代价是需要额外的内存空间。
八、基数排序(Radix Sort)
基数排序的发明可以追溯到1887年赫尔曼·何乐礼在打孔卡片制表机(Tabulation Machine), 排序器每次只能看到一个列。它是基于元素值的每个位上的字符来排序的。 对于数字而言就是分别基于个位,十位, 百位或千位等等数字来排序。
基数排序(Radix sort)是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
1、基本思想
它是这样实现的:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
基数排序按照优先从高位或低位来排序有两种实现方案:
MSD(Most significant digital) 从最左侧高位开始进行排序。先按k1排序分组, 同一组中记录, 关键码k1相等, 再对各组按k2排序分成子组, 之后, 对后面的关键码继续这样的排序分组, 直到按最次位关键码kd对各子组排序后. 再将各组连接起来, 便得到一个有序序列。MSD方式适用于位数多的序列。
LSD (Least significant digital)从最右侧低位开始进行排序。先从kd开始排序,再对kd-1进行排序,依次重复,直到对k1排序后便得到一个有序序列。LSD方式适用于位数少的序列。

2、算法描述
我们以LSD为例,从最低位开始,具体算法描述如下:
①. 取得数组中的最大数,并取得位数;
②. arr为原始数组,从最低位开始取每个位组成radix数组;
③. 对radix进行计数排序(利用计数排序适用于小范围数的特点);
3、代码实现
基数排序:通过序列中各个元素的值,对排序的N个元素进行若干趟的“分配”与“收集”来实现排序。
分配:我们将L[i]中的元素取出,首先确定其个位上的数字,根据该数字分配到与之序号相同的桶中
收集:当序列中所有的元素都分配到对应的桶中,再按照顺序依次将桶中的元素收集形成新的一个待排序列L[]。对新形成的序列L[]重复执行分配和收集元素中的十位、百位…直到分配完该序列中的最高位,则排序结束
1 | /** |
以下是基数排序算法复杂度,其中k为最大数的位数:
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(d*(n+r)) | O(d*(n+r)) | O(d*(n+r)) | O(n+r) |
其中,d 为位数,r 为基数,n 为原数组个数。在基数排序中,因为没有比较操作,所以在复杂上,最好的情况与最坏的情况在时间上是一致的,均为 O(d*(n + r))。
基数排序更适合用于对时间, 字符串等这些整体权值未知的数据进行排序。
Tips: 基数排序不改变相同元素之间的相对顺序,因此它是稳定的排序算法。
基数排序 vs 计数排序 vs 桶排序
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶
- 计数排序:每个桶只存储单一键值
- 桶排序:每个桶存储一定范围的数值
总结
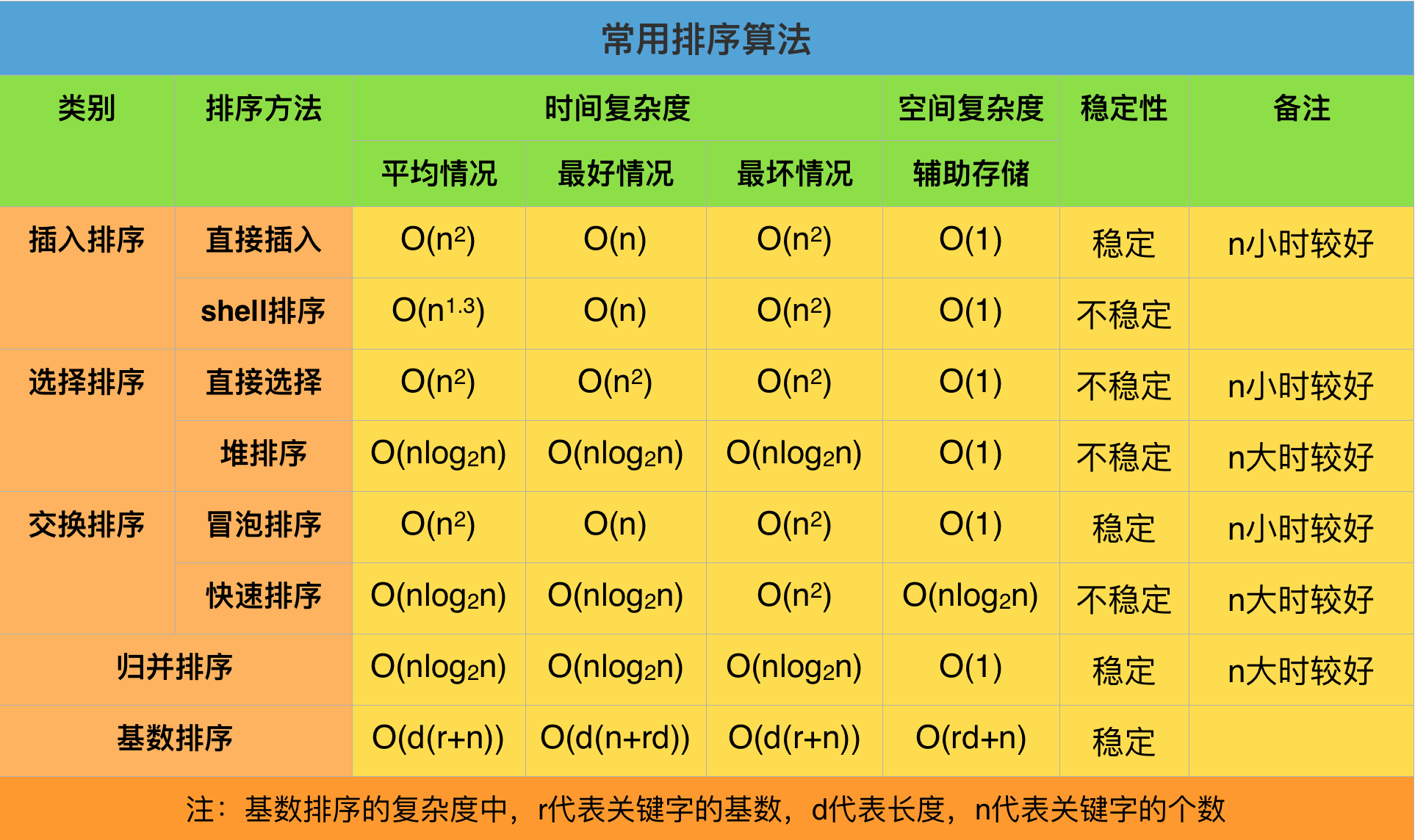
各种排序性能对比如下,有些排序未详细介绍,暂且放到这里。实例测试结果可以看这里:八大排序算法耗时对比 。
| 排序类型 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 |
| 直接插入排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 |
| 折半插入排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 |
| 希尔排序 | O(n^1.3) | O(nlogn) | O(n²) | O(1) | 不稳定 |
| 归并排序 | O(nlog₂n) | O(nlog₂n) | O(nlog₂n) | O(n) | 稳定 |
| 快速排序 | O(nlog₂n) | O(nlog₂n) | O(n²) | O(nlog₂n) | 不稳定 |
| 堆排序 | O(nlog₂n) | O(nlog₂n) | O(nlog₂n) | O(1) | 不稳定 |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(k) | 稳定 |
| 桶排序 | O(n+k) | O(n+k) | O(n²) | O(n+k) | (不)稳定 |
| 基数排序 | O(d(n+k)) | O(d(n+k)) | O(d(n+kd)) | O(n+kd) | 稳定 |
从时间复杂度来说:
(1). 平方阶O(n²)排序:各类简单排序:直接插入、直接选择和冒泡排序;
(2). 线性对数阶O(nlog₂n)排序:快速排序、堆排序和归并排序;
(3). O(n1+§))排序,§是介于0和1之间的常数:希尔排序
(4). 线性阶O(n)排序:基数排序,此外还有桶、箱排序。
到此,很多人会注意到基数排序的时间复杂度是最小的,那么为什么却没有快排、堆排序流行呢?我们看看下图算法导论的相关说明:

基数排序只适用于有基数的情况,而基于比较的排序适用范围就广得多。另一方面是内存上的考虑。作为一种通用的排序方法,最好不要带来意料之外的内存开销,所以各语言的默认实现都没有用基数排序,但是不能否认基数排序在各领域的应用。
时间复杂度极限
当被排序的数有一些性质的时候(比如是整数,比如有一定的范围),排序算法的复杂度是可以小于O(nlgn)的。比如:
- 计数排序 复杂度O( k+n) 要求:被排序的数是0~k范围内的整数
- 基数排序 复杂度O( d(k+n) ) 要求:d位数,每个数位有k个取值
- 桶排序 复杂度 O( n ) (平均) 要求:被排序数在某个范围内,并且服从均匀分布
但是,当被排序的数不具有任何性质的时候,一般使用基于比较的排序算法,而基于比较的排序算法时间复杂度的下限必须是O( nlgn) 。参考很多高效排序算法的代价是 nlogn,难道这是排序算法的极限了吗?
说明
- 当原表有序或基本有序时,直接插入排序和冒泡排序将大大减少比较次数和移动记录的次数,时间复杂度可降至O(n);
- 而快速排序则相反,当原表基本有序时,将蜕化为冒泡排序,时间复杂度提高为O(n2);
- 原表是否有序,对简单选择排序、堆排序、归并排序和基数排序的时间复杂度影响不大。
参考资料
- 数据结构可视化:visualgo,Sorting Algorithms Animations,CodePen & sort it out
- 一个显示排序过程的PYTHON脚本
- 排序算法测试:Lab 1: Sorting - 哥德堡大学课件(University of Gothenburg)
- Sorting Algorithm Animations - 一个排序算法比较的网站
- Sorting - 卡内基梅隆大学课件
- 数据结构常见的八大排序算法(详细整理)
- 必须知道的八大种排序算法【java实现】
- 十大经典排序算法
- 视觉直观感受 7 种常用的排序算法
- JS中可能用得到的全部的排序算法
- 总结5种比较高效常用的排序算法
- 常见排序算法C++总结